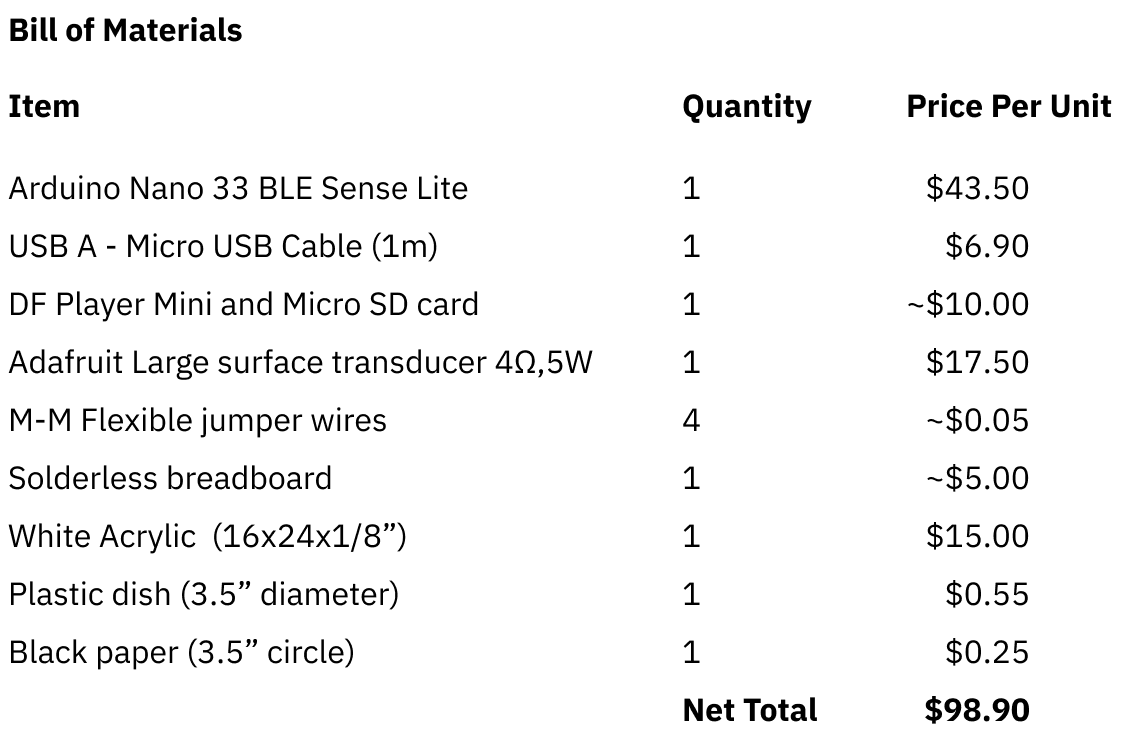
Process
Hardware System
DFPlayer Mini
DFPlayer was a simple device to install, and it could create the sound pretty well for the small devices. During the development process, we found that it requires formatting whenever we want to add or replace the existing sounds. Otherwise, it remembers the previous files and plays the outdated ones.
Speakers
Even though the given output is the mp3 player, we decided to use the sound as a vibration generator. One of the reasons is that the inspiration is the tasseography, which is based on visual patterns. Also, we considered the demonstration environment would be pretty loud that it would be hard to hear the sound there as well. We aimed to create vivid patterns with small particles such as salts. We tried three different speaker parts, including existing Bluetooth speakers. Lastly, we encountered the surface transducer, which turns any surface into a speaker. Unlike the other speakers focused on better sound quality, our aim was focused on the vibration itself, and we didn’t want to have too much other auditory experience other than that. Further, it was also easy for us to place the tray on top of the transducer so that we could avoid physical housing issues.

Fabrication: Laser Cutting & Housing
The physical tools and symbols are important in superstitions and divination. We both wanted to achieve the mood of experience through the Wishwell, on top of the concepts and their interaction. Since we had a chance to learn about laser cutting during this module, it was a good chance to utilize it. Surprisingly it took longer than expected, and it required a substantial amount of time to work on the digital format to make sure that it fits well and cuts the patterns as we wished.
The housing is two nested boxes, one for the support of electronics and also they could be positioned properly to function well; the Arduino was installed closely on the surface since the sound sensor is embedded in there. The other box covers the inside and creates a water ripple on the surface to reflect our concept of Wishwell.

Tiny ML: Edge Impulse
Different from the other software, connecting the Edge Impulse to the Arduino was not intuitive for two reasons. First of all, CLI is unfamiliar with installing the software, and secondly, there was no feedback from Arduino, making us unsure if something was successfully uploaded or not. Following the instruction in this environment, without complete understanding, the installation process reminded us to think the whole process was spooky. In other words, we didn't fully understand what was happening but just followed the instructions. The camera sensor was more complex than the sound classifier. We were mainly trying to capture the word in the sentence, and it made it hard to train the model.
When identifying key words and training the language model in Edge Impulse, a number of challenges and limitations cropped up that affected the reliability and resilience of our model. As a second direction we explored non-verbal audio inputs, experimenting with a water glass xylophone and training based on these pitches, which resulted in a very accurate model. Ultimately, we ended up discarding this exploration as it did not align with our initial narrative. We decided to detect keywords as it was important for participants to explicitly provide inputs with semantic meaning, which was necessary for the underlying logic of the system, and also allowed us to frame the interaction through a familiar point of reference. Instead we constrained our project for the sake of a working proof of concept demo, training the model on 2 key words: "purpose" and "job", as well as noise samples.
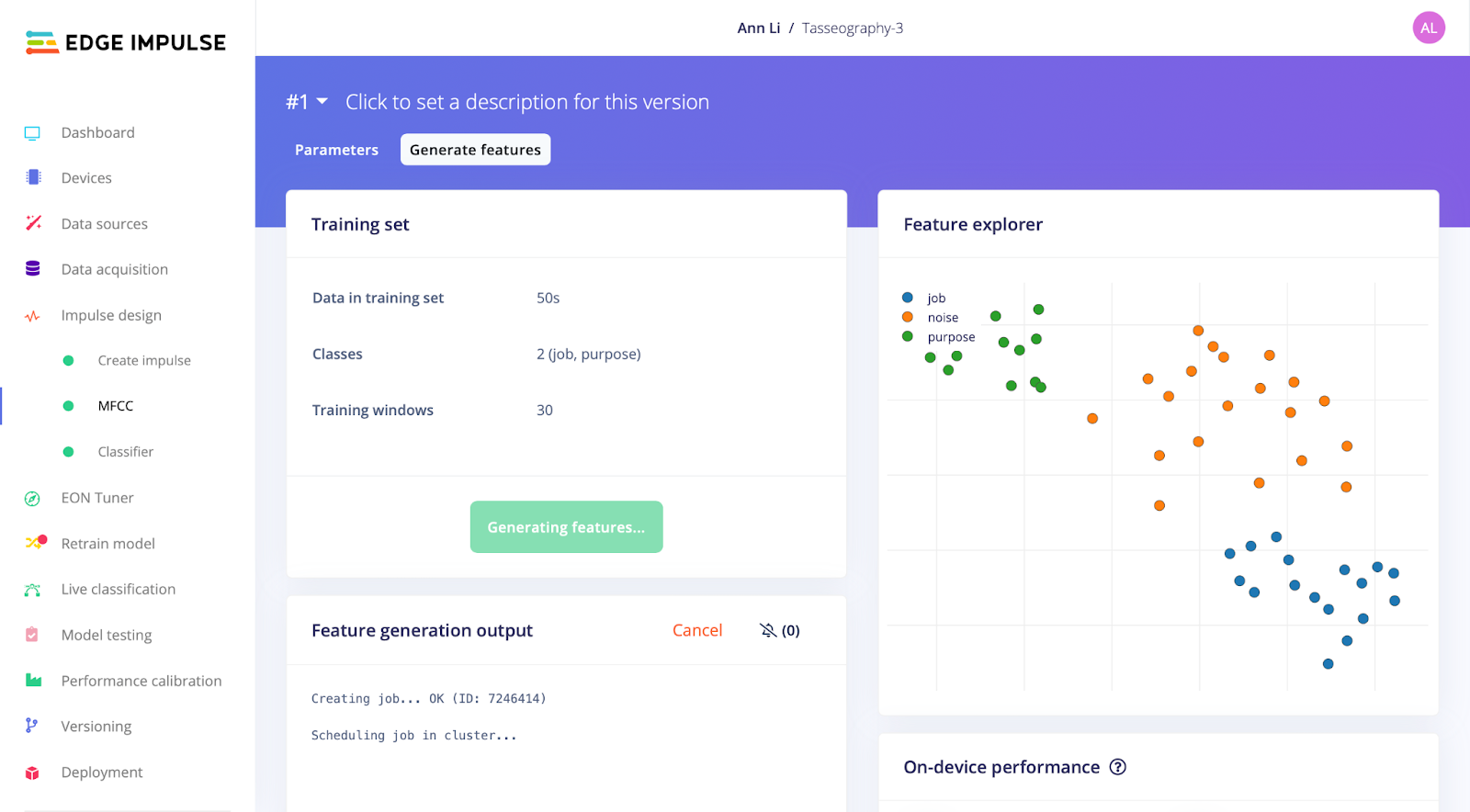
We were quite limited in the number of key terms we are able to provide samples for within the scope of this project, leaving out a range of queries that participants would presumably have been able to submit as inputs. For a proof-of-concept demo however, this was acceptable and we settled on the words “job” and “purpose” to train our model on. Another limitation stemmed from the diversity of voices and contexts the model was trained on– we attempted to include as many Noise samples as possible and record samples from a range of individuals and settings.

ChatGPT
We also visited the generative AI, ChatGPT, and OpenAI Playground, to understand the concept and the possibility of exploring our project. They are more advanced than expected-less errors and quick responses-, on the other, not as advanced as expected-not as conversational as humans. For example, they could answer and summarize the information-based questions very well; however, the experience didn’t feel interactive. The question is always initiated by humans, and they could not lead the conversation as humans. On the other hand, it was incredible to see them having personalities and different answers to the same questions. We both asked, “Do you believe in god?” and the two machines answered totally differently. One machine answered the way more informative about the concept of god, and the other machine answered it/she/he believes in god and it is from its/her/his family religion. It is impossible for them to have the family as a machine. Is it possible for AI to lie? Otherwise, who was the AI referring to family? It was interesting to explore. However, it is hard to engage ChatGPT in our output, an MP3 player, and found that it would not provide the sort of ambiguity central to our narrative and provocation, so we ultimately decided to leave it aside for this project.
Putting it all together
We spent each week learning and understanding the various technologies. Coupling these separated components seemed challenging, but the deployment didn’t require too much hassle. However, the data overflow error during the program's running took some time to debug and revisit each component. It seemed contrary because Edge Impulse required an enormous amount of data to achieve accuracy, and it caused the Arduino to have a hard time running its code. We tried to change the classifier from MFCC to MFE and also tried to change the Arduino library as well.
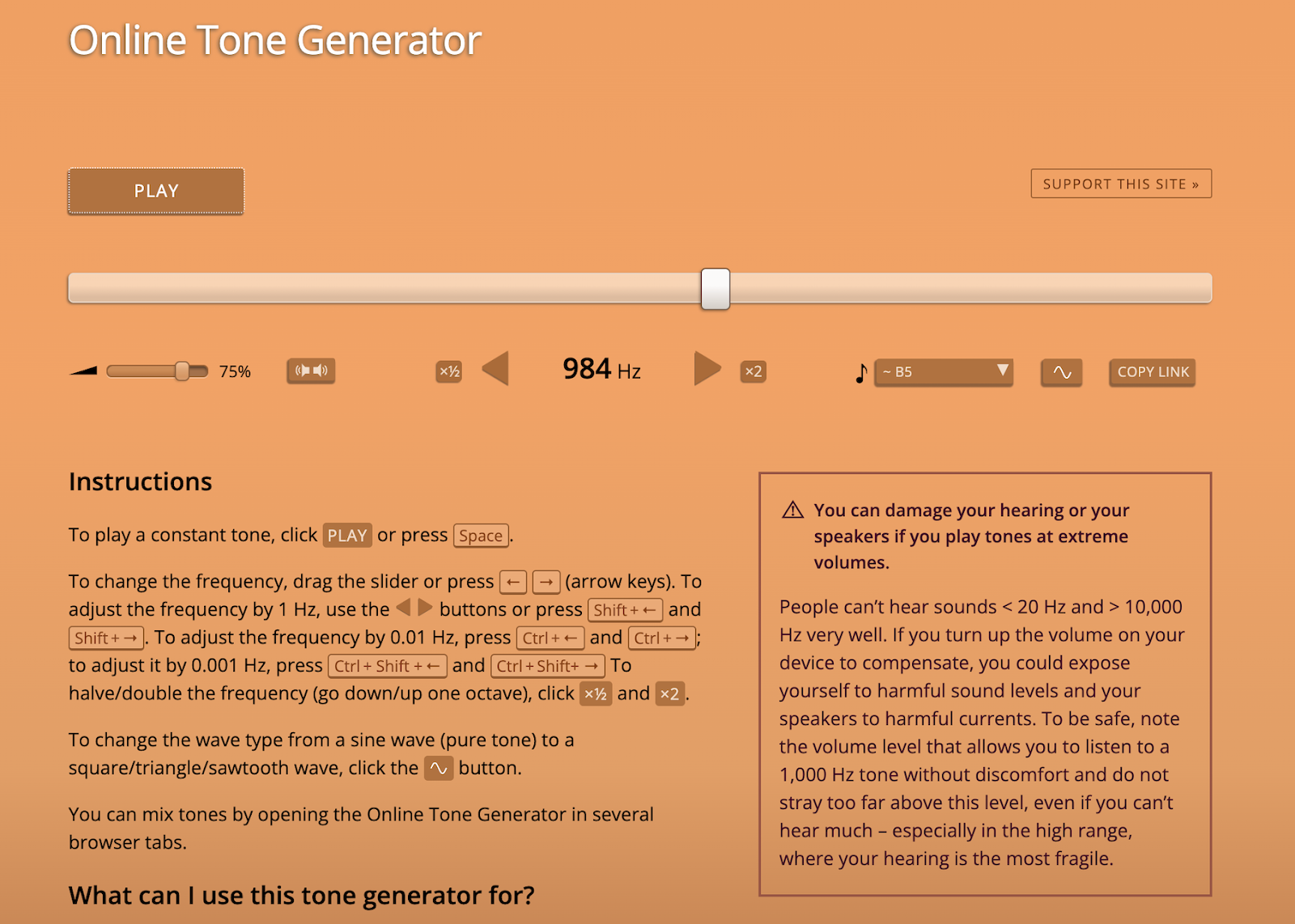
Since we had decided to split up and delegate work towards the end, we came together to connect the fabricated housing and electronics with the trained model. We also changed the sound to be a single tone, 345Hz, 984Hz, and 1820Hz. 1820Hz was not only painful to listen to the sound, but also it didn’t create any pattern with the salt. To allow enough time to create the pattern and also let people enjoy the movement, each sound is about 9 seconds.
Content Rating
Is this a good/useful/informative piece of content to include in the project? Have your say!
You must login before you can post a comment. .