The goals
The intent of this project was to analyze tweets posted throughout Pittsburgh to gain a sense of its characteristics based on descriptive words used throughout tweets. In theory the collection of words could be used to create a word cloud that would show the describing characteristics of neighborhoods based on tweets tweeted in those areas.
Approach and process
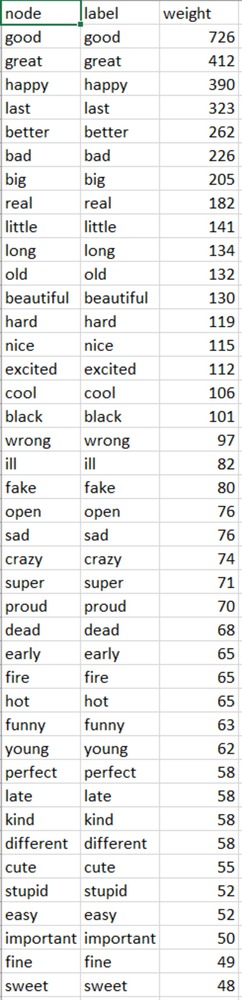
A dataset of selected adjectives was scraped from PGH Twitter last week.
This data will be used in Wordaizer, to form a word cloud of the city that will allow us to see the most common descriptive words used throughout PGH tweets.
Dataset
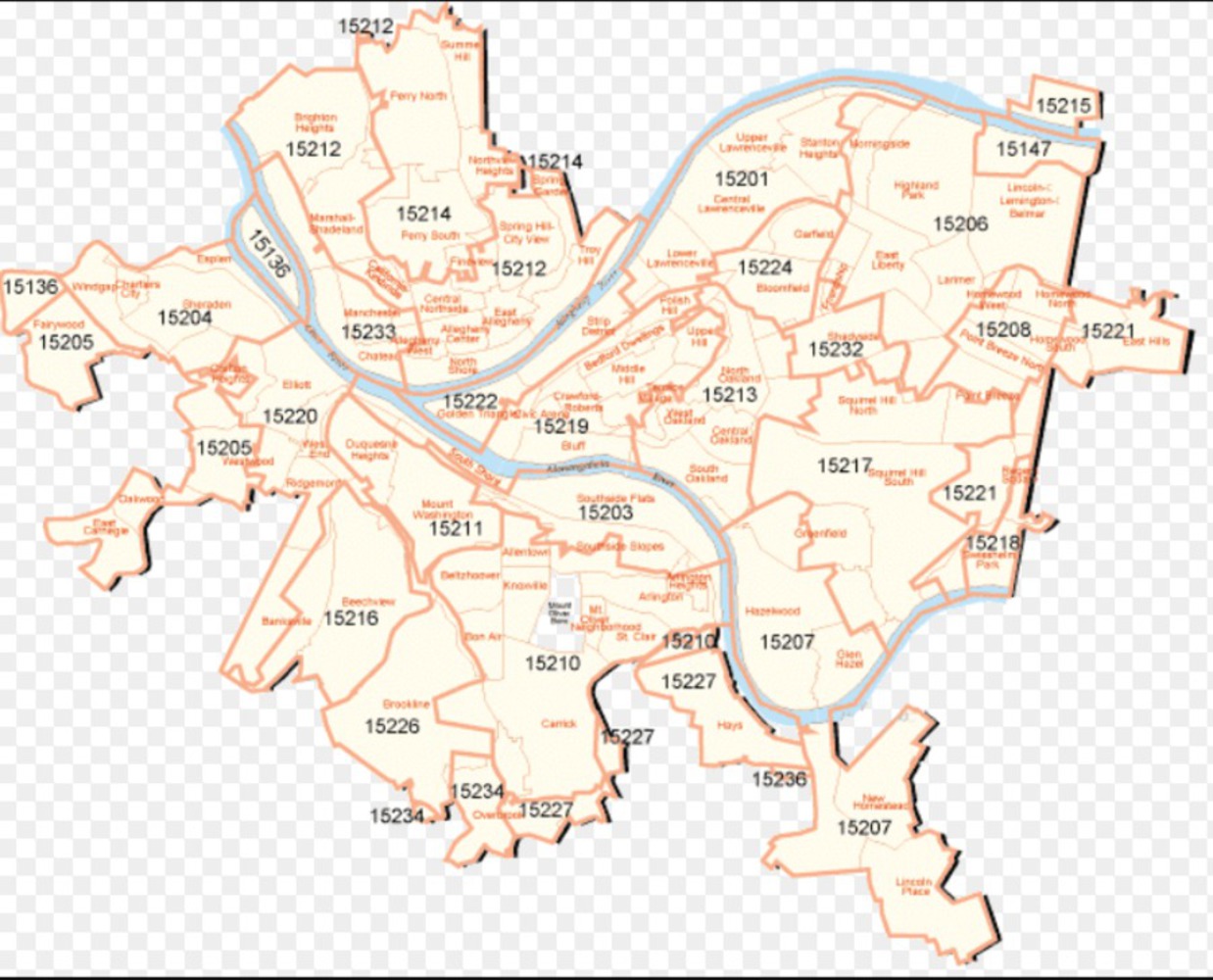
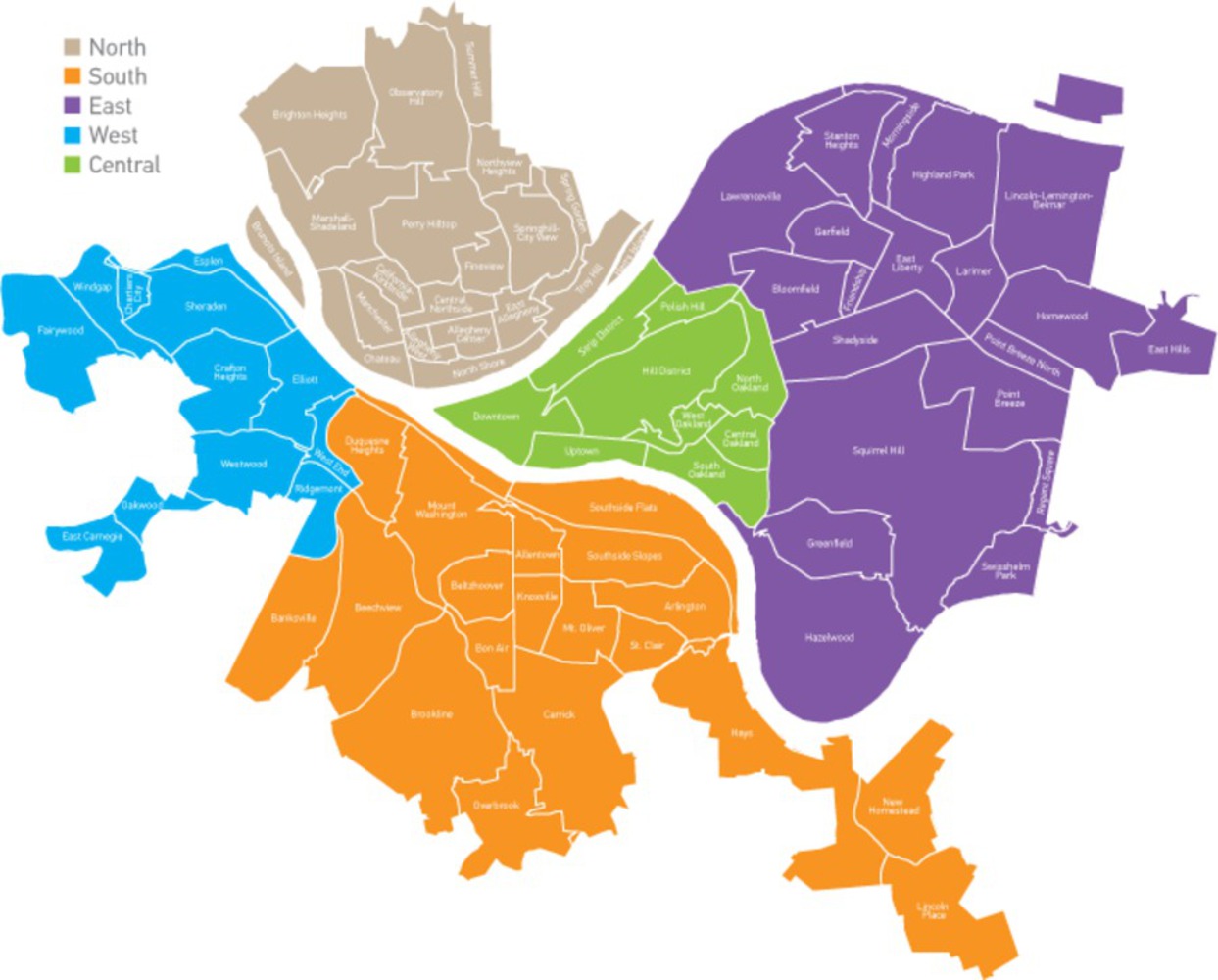
The dataset is a week of scraped twitter data, sorted via postal codes and arranged into the different regions of Pittsburgh- North, South, East, West and Central.
A target list of adjectives was used to pull counts from the tweets. From this we can see which regions tweet which adjectives the most.
Again, the postal codes of each region was combined to one text file that registered the count of each time the adjective was tweeted.