Part 2: Working with GPT-3
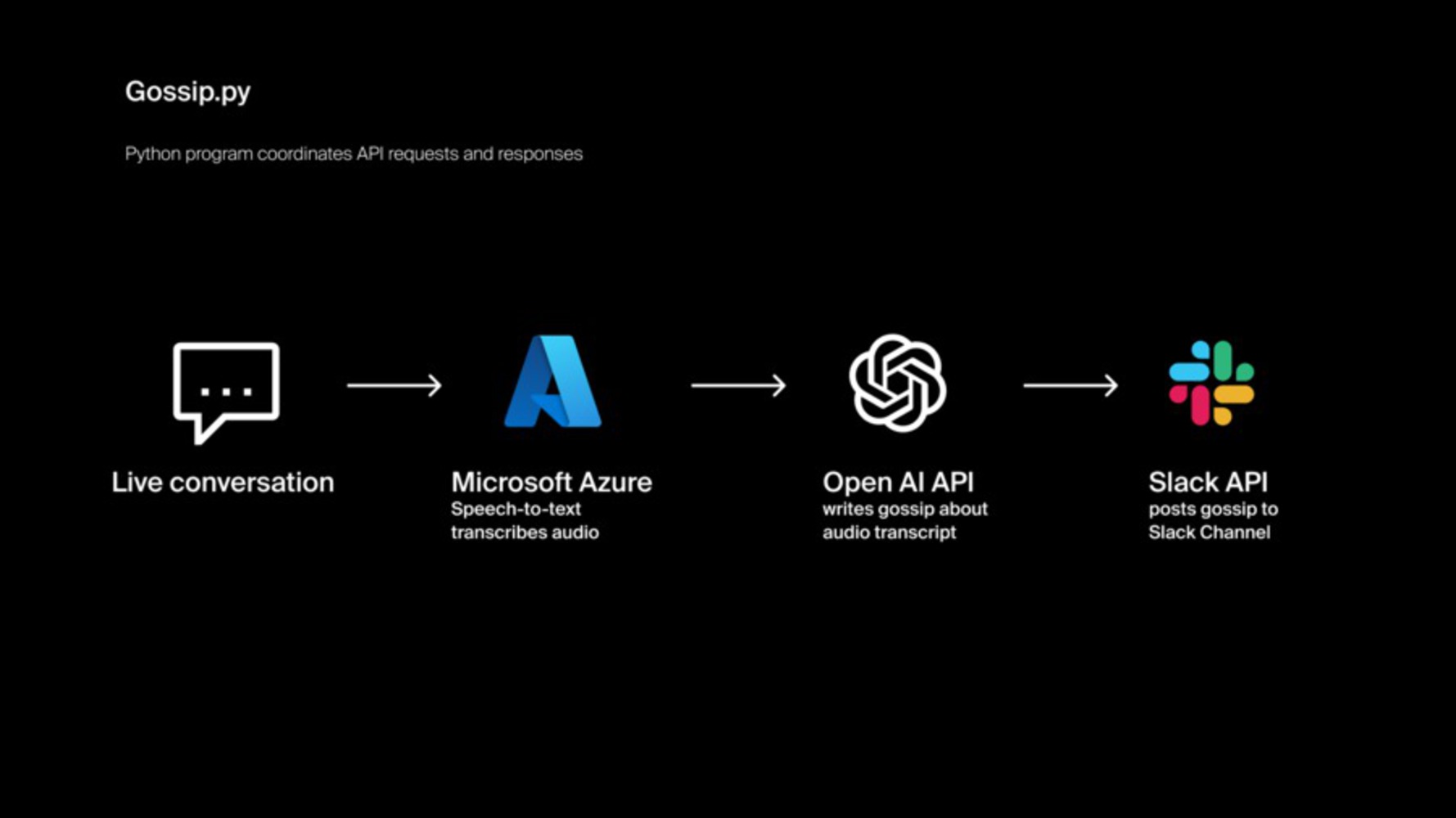
Since we wanted this device to make inferences and the device had to be 'fickle', we had to find software that would be able to generate responses without us needing to write exact conditions for all possible scenarios. This quickly ruled out Alexa since it is based heavily on conditional logic. Open AI's GPT-3 was our ideal choice and became the main mode of interpretation and responding.
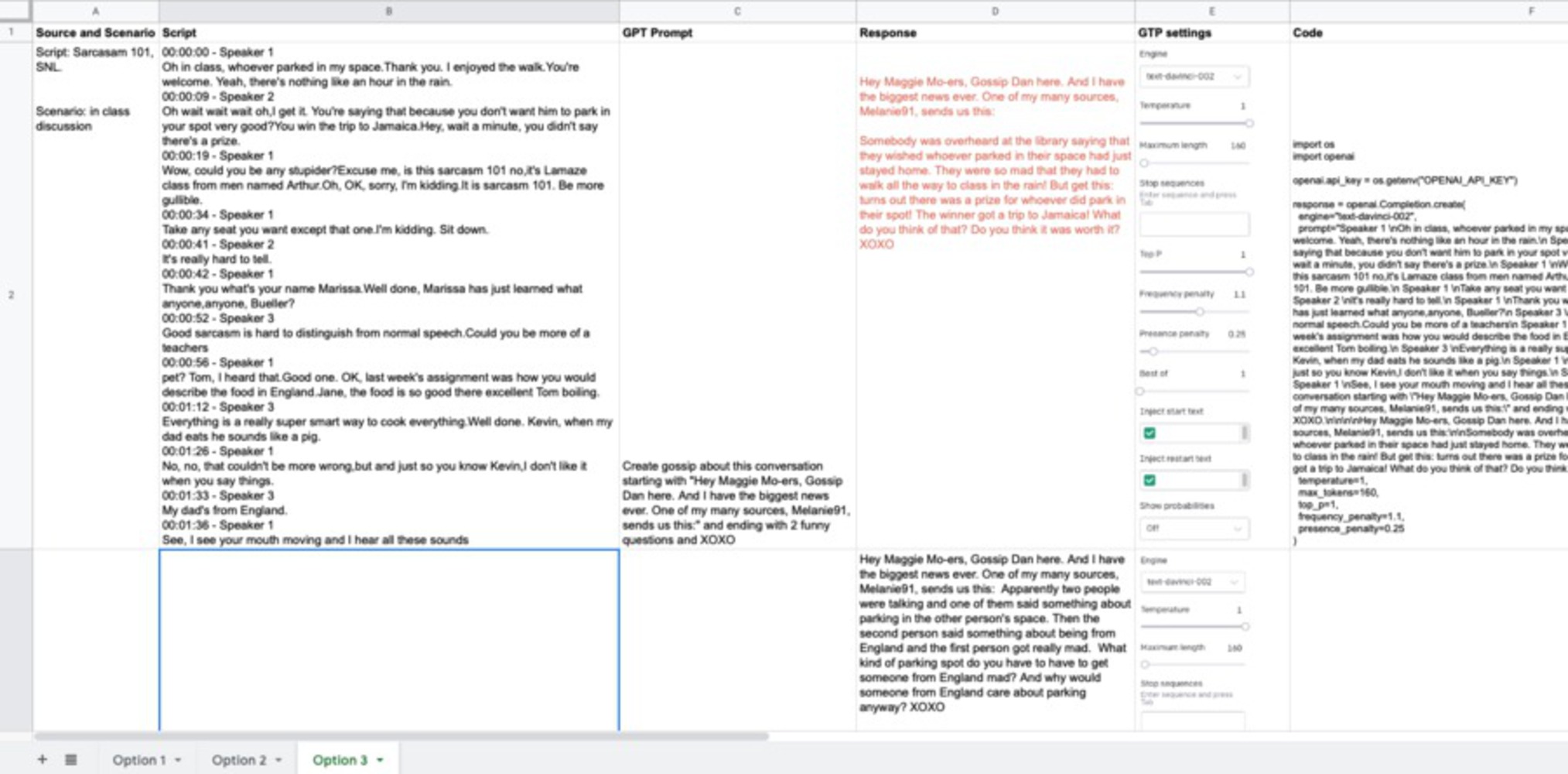
We spent a good amount of time experimenting with GPT 3 for our prototype. The first iteration started with writing a script for two people conversing in a studio setting about a group project. This script had names and corresponding dialogues, which our actual device would never be able to produce in terms of the fidelity as well as the names of the speakers because at this point in the process it's acting as a mere recorder. However, it gave as a good start to first get a hang of tweaking the GPT 3 parameters and how they created different outcomes. We went through about 15 scripts and multiple variations of adjusting three parameters before we started receiving responses that seems like a good balance of what we fed and what GPT 3 gave as an output.
Parameter 1: Prompt: The obvious one is to ask GPT to write a summary for the script, but the outcome wasn’t playful by any means. We tried two three other variations before literally asking it to create a gossip based on the above text, which worked much better. We borrowed the personality of Gossip girl and wrote our ghost story in a similar format, and realized that specific text and format could be included in the command like start with “Hey….” And end with two funny questions and XOXO.
Parameter 2: Presence Penalty: The description said this means that the likelihood to talk about new topics would increase with this and we found this to be a really interesting feature because it added randomness to the outcome.
Parameter 3: Maximum length: This was tricky in finding the right balance because we didn’t want the gossip to be too long or descriptive yet not too short to feel like a tweet. We finally settled on around 260 tokens given that we were commanding GPT 3 to start and end the response with a specific sentence.