Technology prototype
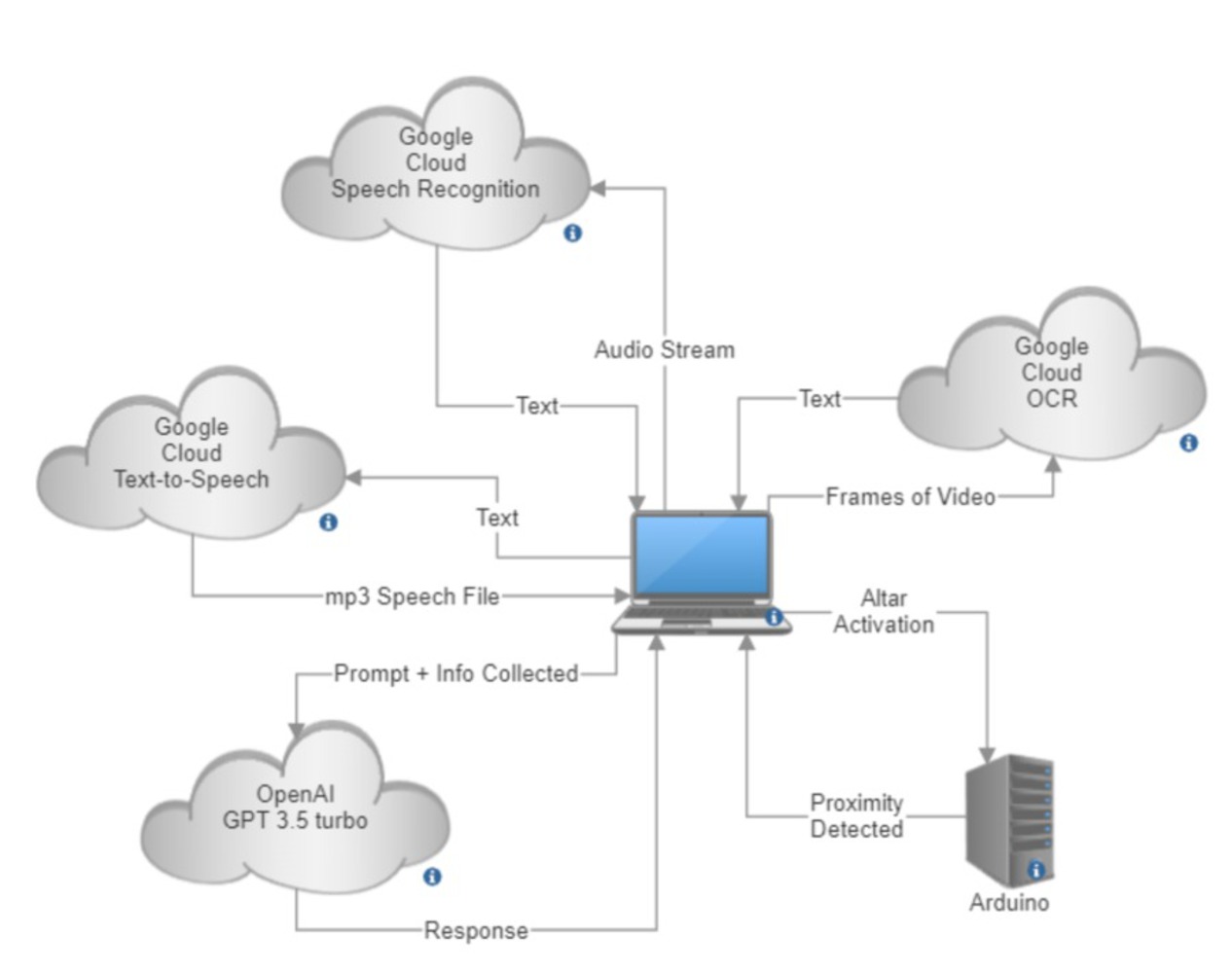
Work done on the software side of things started with a research phase to determine the best solution for what we had in mind initially - text-to-speech, speech-to-text, and optical character recognition (OCR). After exploring alternatives such as OpenCV, we decided that Google Cloud would be the best option, as it offered better accuracy and if we used the services within a 3 month timeframe after signing up, we could use the free trial credits.
Afterwards, we focused on preparing a proof of concept for the demo. Given that we were unfamiliar with Google Cloud, we decided to utilize sample code provided by Google on Github and alter it for our specific needs. We added basic modifications to the code and a wrapper function to run through the functionality we planned on achieving, but at the time there was little done in the department of user experience or protection against crashes. By the demo, we had:
- After receiving an OCR input, specific values would be fed into openAI large language learning model using a predetermined prompt
- Following receiving the response from ChatGPT, the text-to-speech would be done through Google Cloud
- Speech to text done through Google Cloud
- A stream would be opened and close after 1 input.
- Participants would be prompted by us to ask the computer a question.
- We created a “form” for people to fill out and fed the sanitized output to Google Cloud
After the demo and following finalizing our design we began to more heavily alter the sample code. As a result of the feedback we received from the demo, we also attempted to get a bit more ambitious. On the coding side of things, this meant more user interaction for a better experience. So, moving forward we primarily focused on a smooth user experience while also attempting to get the program to run through cycles automatically. This meant we needed ways to prompt the user automatically. Simultaneously though, we need to figure out ways to minimize the overall amount of user input, as increased input would in turn mean an increased surface area to cover for bugs and errors. Unfortunately, perhaps due to increased ambitions for a smoother user experience, we did not successfully find the healthy balance we wanted.
During this process, testing was done consistently but assumptions had to be made, as the physical environment was not ready or available to be used for much of the process. Unfortunately this side-by-side development timeline cost us, as we were not able to as thoroughly test our code as we hoped. Although we integrated the physical and computing sides of the project as soon as components were complete, a combination of lack of time but also lack of creativity meant that not all use cases were tested by the time the showcase arrived. This unfortunately meant a rough start to the showcase, where attempts to fix new bugs actually ended up making things worse. However, a workaround was found and for most of the exhibition, things ran smoothly.