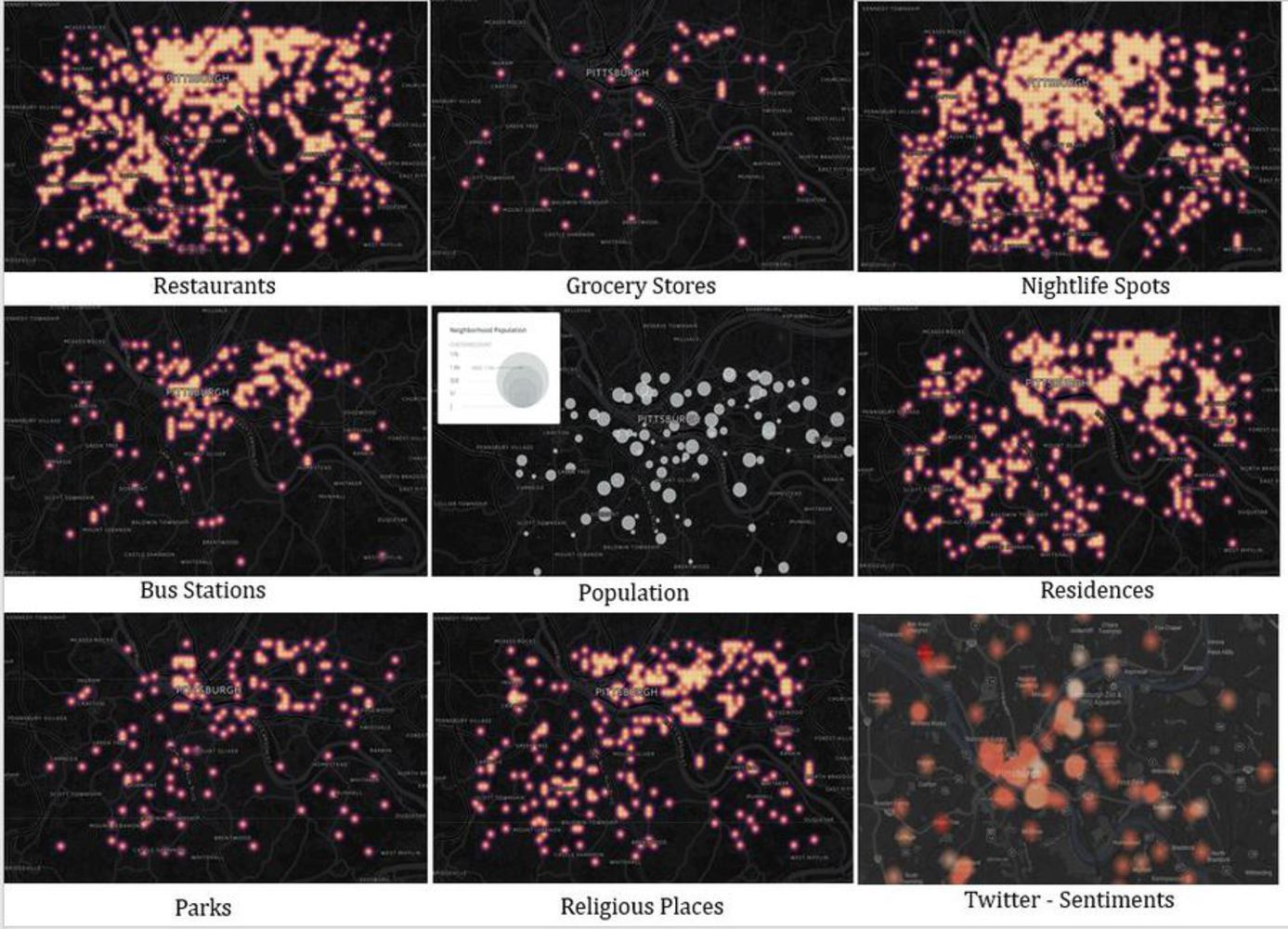
Are you moving to a new neighborhood?
Made by shivamm
Made by shivamm
The goal of this project is to identify neighborhoods which are particularly attractive to move into based on the social data we have.
Created: October 30th, 2017
The goal of this project is to identify neighborhoods which are particularly attractive to move into based on the social data we have.