Reflection
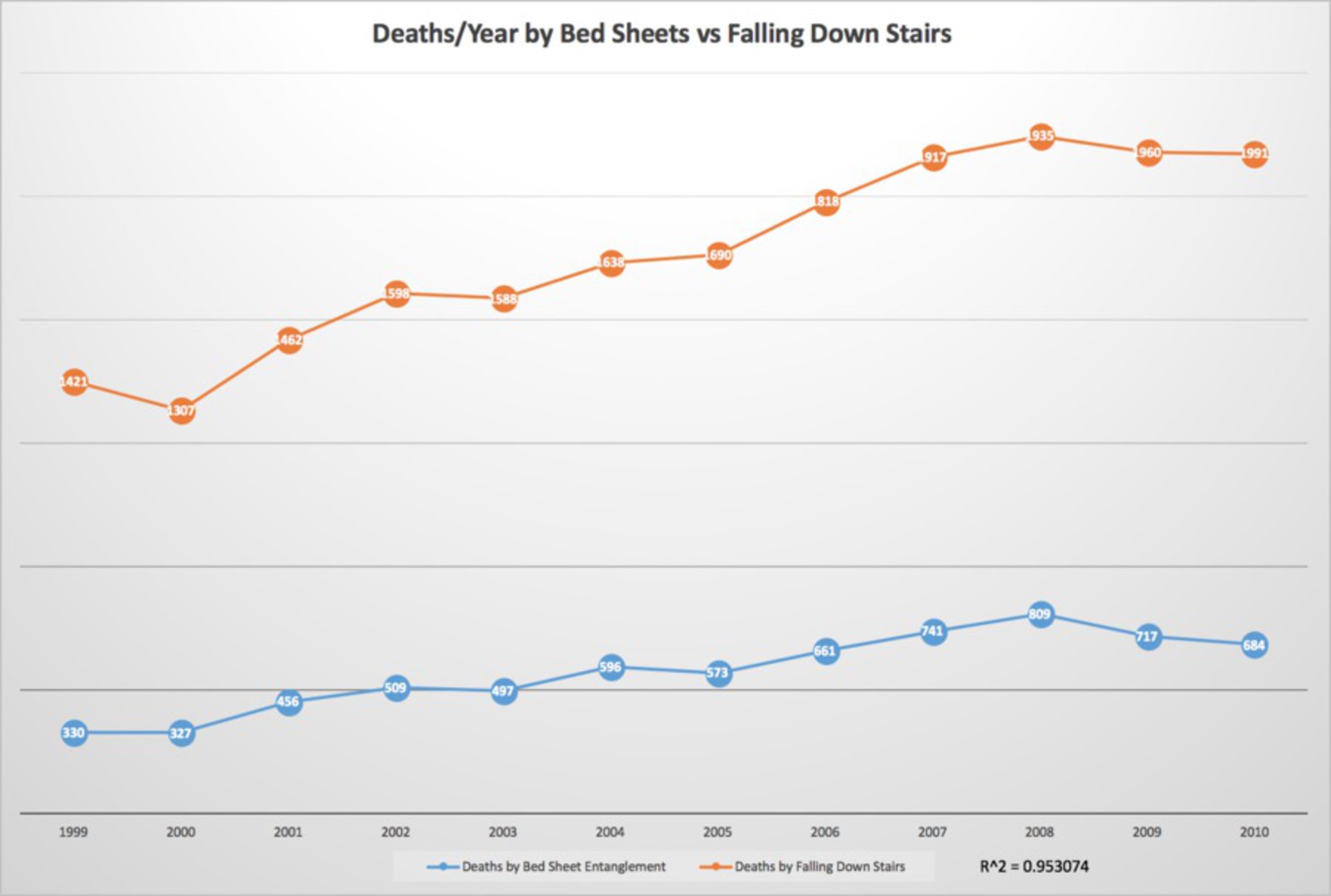
I think that the outcome of the project was kind of simple, despite all of the time that went into finding correlating data. If I found an easier way to find data that correlated well like this, I would have liked to design a series of graphs that starts out with variables that seem like they could be related, then slowly progressing to graphs that have more and more unrelated variables to the point where it's ridiculous for them to be correlated at all.
However, doing this project has certainly taught me to be wary of graphs on initial inspection. We are even taught in school that the closer the r^2 value of a graph is to 1, the more closely-related the variables of the graph are. However, this is a clear example of a way to completely take advantage of this fact to create fake ideas that appear mathematically sound. How many "official" scientific findings or news studies have made conclusions that are actually incorrect because we believe that the data seems to correlate?