Refined Alexis of Delphi
Made by Saloni Gandhi and Dillon Shu
Made by Saloni Gandhi and Dillon Shu
Created: May 9th, 2023
Alexis of Delphi
Dillon Shu is a senior studying Information Systems. He worked on most of the virtual back-end aspects such as text-speech, speech-to-text, and character recognition. Saloni Gandhi is a senior studying Information Systems, Human-Computer Interaction, and Physical Computing. She worked on the physical aspects and the overall user experience such as designing the altar, figuring out the various interactions the user would have during the experience.
Ancient Greek legends of the Oracle of Delphi are stories of fortune telling and sacrifice. Its modern day counterpart has now arrived. In today’s technological era, we are constantly “sacrificing” our personal information and privacy in the name of ease of use. Alexis of Delphi is a virtual assistant that only helps you at a cost, the cost of information.
Activate Alexis by offering your hand and sacrificing a piece of personal information in exchange for a chance to ask a question. Watch Alexis consume your personal information and add it to her collection. Ask her any question you want and get a whiff of her knowledge.
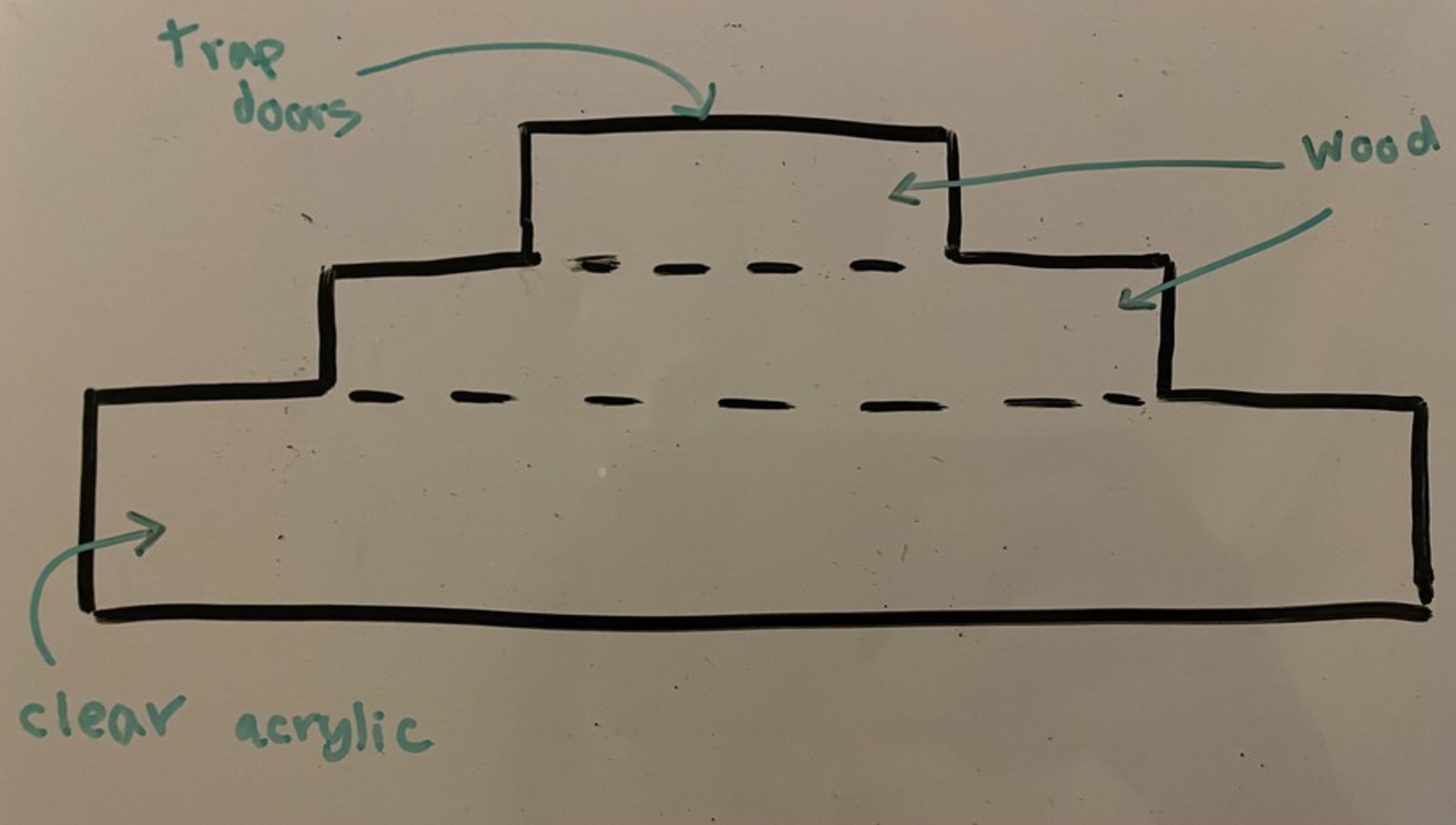
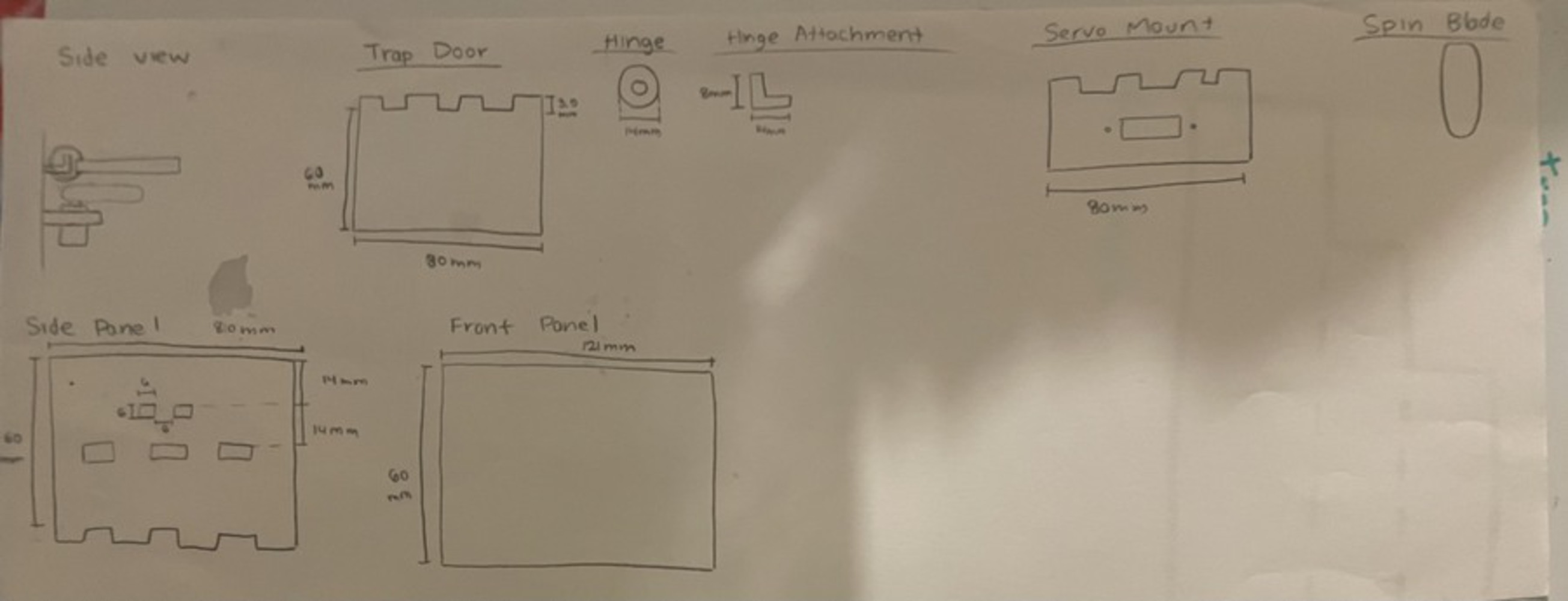
To start off the process of building the physical prototype, I began by brainstorming ideas on what the dropping mechanism would consist of and what the overall product would look like. In the previous iteration, I had used dc motors to power the mechanism. I quickly realized that the functionality of these motors are limited and they are difficult to mount. For this iteration, I decided on using servo motors to power the dropping mechanism. After exploring all my ideas, I finalized on the idea of using trap doors. The idea would look something like this:
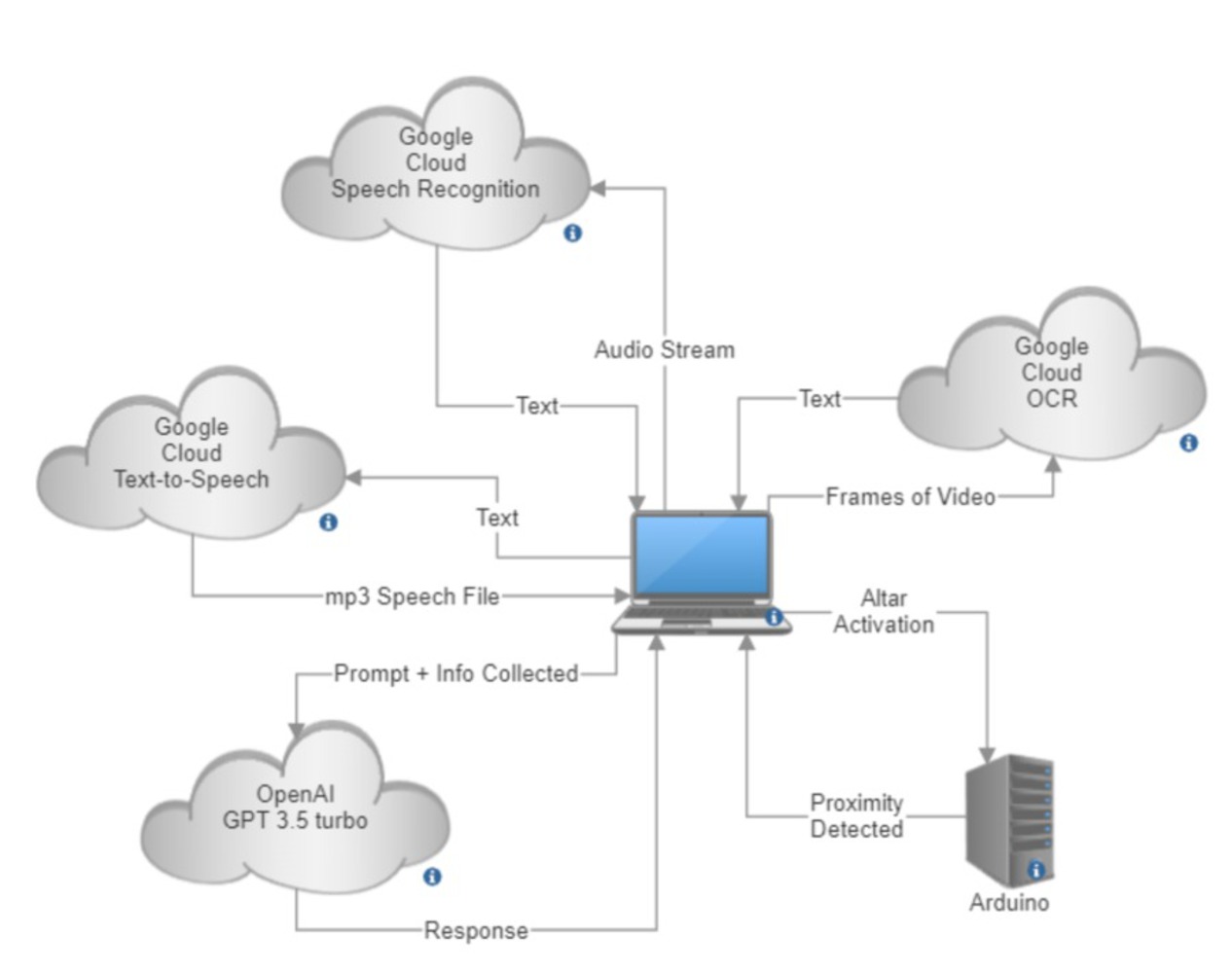
Work done on the software side of things started with a research phase to determine the best solution for what we had in mind initially - text-to-speech, speech-to-text, and optical character recognition (OCR). After exploring alternatives such as OpenCV, we decided that Google Cloud would be the best option, as it offered better accuracy and if we used the services within a 3 month timeframe after signing up, we could use the free trial credits.
Afterwards, we focused on preparing a proof of concept for the demo. Given that we were unfamiliar with Google Cloud, we decided to utilize sample code provided by Google on Github and alter it for our specific needs. We added basic modifications to the code and a wrapper function to run through the functionality we planned on achieving, but at the time there was little done in the department of user experience or protection against crashes. By the demo, we had:
- Following receiving the response from ChatGPT, the text-to-speech would be done through Google Cloud
After the demo and following finalizing our design we began to more heavily alter the sample code. As a result of the feedback we received from the demo, we also attempted to get a bit more ambitious. On the coding side of things, this meant more user interaction for a better experience. So, moving forward we primarily focused on a smooth user experience while also attempting to get the program to run through cycles automatically. This meant we needed ways to prompt the user automatically. Simultaneously though, we need to figure out ways to minimize the overall amount of user input, as increased input would in turn mean an increased surface area to cover for bugs and errors. Unfortunately, perhaps due to increased ambitions for a smoother user experience, we did not successfully find the healthy balance we wanted.
During this process, testing was done consistently but assumptions had to be made, as the physical environment was not ready or available to be used for much of the process. Unfortunately this side-by-side development timeline cost us, as we were not able to as thoroughly test our code as we hoped. Although we integrated the physical and computing sides of the project as soon as components were complete, a combination of lack of time but also lack of creativity meant that not all use cases were tested by the time the showcase arrived. This unfortunately meant a rough start to the showcase, where attempts to fix new bugs actually ended up making things worse. However, a workaround was found and for most of the exhibition, things ran smoothly.
Source Code: https://drive.google.com/drive/u/0/folders/1pq4IPJ9hVVvO9r2mEMvYqPFYoBaNcZFT
3D files: https://drive.google.com/drive/folders/1jgI0qP5ilfLkb1CFo6jGMwmGsfdzvLs2?usp=share_link
Overall, this project was quite successful. We incorporated many different technical pieces and combined them into a single user experience. We were a bit ambitious, and that hurt us in the beginning of the exhibition, but we don’t regret that. We wish that we would have achieved all of our goals for user experience, but given the time frame it was challenging. That said, when everything started falling into place it made it all the more satisfying.
~